

Narzędzia i strategie używane do tworzenia kopii zapasowych plików różnią się w zależności od tego, czy tworzymy kopie działającego systemu. W niniejszym artykule przedstawimy zagrożenia związane z korzystaniem z popularnych narzędzi Linuksa do tworzenia kopii zapasowych żywych danych i przeanalizujemy niektóre alternatywy.
Istnieje mnóstwo narzędzi do tworzenia kopii zapasowych, zaś w Internecie można znaleźć mnóstwo samouczków wyjaśniających, jak z nich korzystać. Niestety, większość blogów i artykułów na poziomie podstawowym zakłada, że użytkownik chce jedynie wykonać kopię zapasową niewielkiego zestawu danych, które pozostają statyczne przez cały proces tworzenia kopii zapasowej.
Takie założenie jest w wielu przypadkach akceptowalnym przybliżeniem. W końcu użytkownik, który wykonuje kopię zapasową katalogu ze zdjęciami, prawdopodobnie w trakcie tego procesu nie otworzy edytora obrazów i nie zacznie losowo modyfikować plików podczas ich przesyłania. Jednak w praktyce trzeba często wykonywać kopie zapasowych danych, które są modyfikowane. Rozważmy na przykład aplikację internetową, która jest mocno obciążona i musi cały czas działać, również podczas tworzenia kopii zapasowej.
Pułapka: popularne narzędzia
Tradycyjne narzędzia uniksowe, takie jak Dd, Cpio, Tar czy Dump, dobrze radzą sobie z archiwizacją statycznych danych, ale niespecjalnie nadają się do robienia migawek z folderu pełnego żywych danych, przy czym niektóre radzą sobie z tym gorzej niż pozostałe.
Jeśli np. program działający na poziomie systemu plików próbuje skopiować plik, w którym właśnie są zapisywane dane, może on umieścić uszkodzoną wersję pliku w kopii zapasowej (Rysunek 1). Jeśli uszkodzenie dotyczy pliku, którego format ma prostą strukturę (na przykład pliku tekstowego), może to nie stanowić wielkiego problemu, ale pliki o złożonym formacie mogą stać się bezużyteczne.

Narzędzia działające na poziomie urządzenia blokowego są szczególnie podatne na problemy, gdy są używane na aktywnych systemach plików. Program taki jak Dump omija interfejsy systemu plików i bezpośrednio odczytuje zawartość fizycznie przechowywaną na dysku twardym. Chociaż takie podejście ma szereg zalet [1], niesie ze sobą duże obciążenie. Gdy system plików jest w użyciu, wykonywane na nim operacje zapisu trafiają do pamięci podręcznej, którą zarządza jądro – nie są od razu zapisywane na dysku. Z punktu widzenia użytkownika, gdy plik jest zapisywany, operacja może wyglądać na natychmiastową, ale w istocie dany plik będzie istniał w pamięci RAM aż do momentu, gdy jądro zapisze go na dysku.
Tak więc rzeczywiste dane przechowywane na dysku będę nieco chaotyczne, potencjalnie składające się z częściowo napisanych plików, które czekają, aż jądro scali je w przyszłości. Próba odczytania zawartości dysku za pomocą Dumpa lub Dd może zwrócić niekompletne dane, a tym samym wygenerować wadliwą kopię zapasową.
Listing 1: Skrypt kopii zapasowej dla serwera osobistego
01 #!/bin/bash
02
03 # Skrypt napisany w celach edukacyjnych i przetestowany pod Devuan. Uwaga:
04 # nie zawiera obsługi błędów – nie należy go używać na serwerach produkcyjnych!
05
06 # Zatrzymaj usługi korzystających z folderów, które chcesz zarchiwizować.
07
08 /etc/init.d/apache2 stop
09 /etc/init.d/mysql stop
10
11 # Poinstruuj system operacyjny, aby zatwierdził oczekujące instrukcje zapisu
12 # na dysku twardym.
13
14 /bin/sync
15
16 # Utwórz kopię zapasową za pomocą Tara i wyślij dane do zdalnego hosta przez SSH.
17 # Uwierzytelnianie za pomocą klucza publicznego SSH musi być skonfigurowane wcześniej,
18 # jeśli skrypt ma być uruchamiany bez nadzoru.
19
20 /bin/tar --numeric-owner -cf - /var/www /var/mariadb 2 >>
21 /dev/null | ssh debug@someuser@example.org "cat - > backup_`date -I`.tar"
22
23 # Restart usług
24
25 /etc/init.d/mysql start
26 /etc/init.d/apache2 start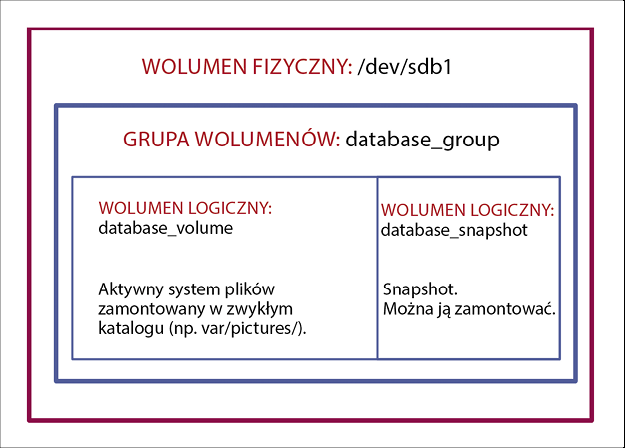
Kompromisowe rozwiązanie
Klasyczne rozwiązania uniksowe są dojrzałe i dobrze przetestowane, zaś administratorzy mają dobre powody, by z nich stale korzystać. Fakt, że nie nadają się do tworzenia kopii zapasowych katalogów poddanych dużemu obciążeniu nie powinien przeszkadzać, prawda?
Jeśli narzędzie do tworzenia kopii zapasowych nie działa niezawodnie na obciążonym katalogu, oczywistą opcją jest usunięcie obciążenia przed utworzeniem kopii zapasowej katalogu. Jest to z pewnością wykonalne na komputerze stacjonarnym: możemy po prostu powstrzymać się od modyfikowania zawartości folderu ze zdjęciami podczas ich archiwizacji za pomocą polecenia tar.
W przypadku serwerów to podejście jest bardziej złożone. Hobbystyczny serwer osobisty z pewnością może pozwolić sobie na wyłączenie usługi w celu wykonania kopii zapasowej, o ile jest ona wykonywana w czasie, gdy żaden użytkownik z niej nie korzysta. Na przykład, jeśli nasz osobisty blog, który ma 15 odwiedzin dziennie, znajduje się w /var/www, a powiązana z nim baza danych znajduje się w /var/mariadb, możemy utworzyć zadanie Crona, które wyłączy serwer WWW i bazę danych, wywoła synchronizację, wykona kopię zapasową obu folderów, a następnie ponownie uruchomi wszystkie usługi. Zarchiwizowanie małej witryny może zająć kilka minut i nikt nie zauważy, jeśli zrobimy to w czasie, gdy nasi goście śpią (Listing 1).
Natomiast w przypadku serwerów produkcyjnych zatrzymanie usług w celu wykonania kopii zapasowej po prostu nie wchodzi w grę.
Na kłopoty – COW
Popularnym rozwiązaniem problemu tworzenia kopii zapasowych systemów plików, gdy są one obciążone, jest użycie pamięci masowej obsługującej mechanizm COW (Copy-on-write). Co to znaczy?
Kiedy plik jest otwierany i modyfikowany w klasycznym systemie plików, system plików zazwyczaj zastępuje stary plik nową wersją pliku. Natomiast pamięć masowa z obsługą COW ma inne podejście: nowa wersja pliku jest zapisywana w wolnej lokalizacji systemu plików, a lokalizacja starego pliku może być nadal zarejestrowana. Wynika z tego, że podczas modyfikowania pliku system plików nadal przechowuje wersję pliku, o której wiadomo, że jest dobra.
Jest to niezwykle przydatne rozwiązanie, ponieważ upraszcza robienie migawek obciążonych systemów plików. Sterownik pamięci masowej może zostać poinstruowany, aby utworzyć migawkę w bieżącym dniu. Jeśli plik jest modyfikowany podczas wykonywania migawki, zamiast niego zostanie użyta stara wersja pliku, ponieważ wiadomo, że stara wersja jest w stanie spójnym, podczas gdy zapisywana nowa wersja – niekoniecznie.
ZFS to popularny system plików z obsługą COW. Ponieważ zajmuję się głównie systemami BSD, uważam ZFS za nieco kłopotliwe rozwiązanie dla niewielkiego serwera Linuksowego. We FreeBSD ZFS jest niemal natywnym rozwiązaniem, natomiast w świecie Linuksa jawi się jako outsider, mimo że stale zyskuje na popularności.
Z drugiej strony, Linux od kilku lat ma natywne narzędzie do tworzenia migawek: LVM (Menedżer woluminów logicznych). Jak sama nazwa wskazuje, LVM jest przeznaczony do zarządzania woluminami logicznymi. Jego główną zaletą jest elastyczność, ponieważ pozwala administratorom dodawać więcej dysków twardych do komputera, a następnie używać ich do zwiększenia pojemności istniejących systemów plików. Natomiast o funkcji tworzenia migawek często się zapomina.
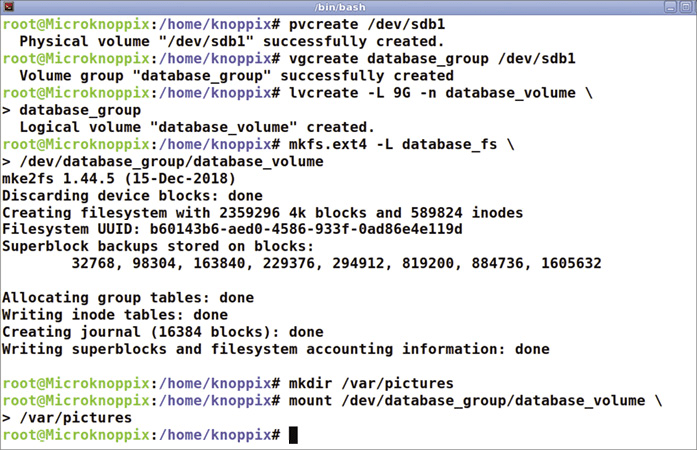
Główną wadą korzystania z LVM do migawek jest fakt, że wszystko trzeba rozplanować z dużym wyprzedzeniem. Załóżmy, że zamierzasz wdrożyć bazę danych przechowującą dane aplikacji w /var/pictures. Aby móc w przyszłości robić z migawki LVM, należy w pierwszej kolejności utworzyć system plików, który zamierzamy zamontować w /var/pictures. W tym celu partycja na dysku twardym musi być za pomocą pvcreate oznaczona jako Wolumin fizyczny – w niej znajdzie się kontener LVM. Następnie musimy w nim utworzyć Grupę woluminów, używając vgcreate (Rysunek 2). Wreszcie za pomocą lvcreate musimy wewnątrz grupy Grupa woluminów utworzyć Wolumen logiczny i sformatować go (Rysunek 3).
Należy przy tym uważać, aby w przyszłości w Grupie woluminów zostawić trochę wolnego miejsca na przechowywanie migawek. Obszar migawek nie musi być tak duży, jak system plików, którego kopię zapasową zamierzamy utworzyć, ale jeśli możemy sobie na to pozwolić, jest to wskazane (patrz ramka „Jak działają migawki LVM?”).
Jeśli pewnego dnia będziemy musieli wykonać kopię zapasową /var/pictures, wolumin migawki utworzymy jednym poleceniem, takim jak:
lvcreate -L 9G -s -n database_snapshot/dev/database_group/database_volumeNastępnie można zamontować wolumin migawki jak zwykły system plików w dowolnym katalogu:
mkdir /var/pictures_snapshot
mount -o ro /dev/database_group/database_snapshot/var/pictures_snapshotPo zamontowaniu migawki możemy skopiować jej zawartość za pomocą dowolnego narzędzia, takiego jak Rsync, i przenieść ją do miejsca, gdzie przechowywane są kopie zapasowe. Pliki w /var/pictures_snapshot są niezmienne i można je skopiować, nawet jeśli w tym czasie zawartość /var/pictures jest modyfikowana.
Jak działają migawki LVM?
Wolumin migawki LVM w rzeczywistości nie zawiera kopii wszystkich plików, które znajdowały się w oryginalnym systemie plików, kiedy wykonywano migawkę.
Kiedy wykonywana jest migawka, menedżer woluminów odnotowuje stan oryginalnego systemu plików w czasie wykonywania migawki. Gdy plik zostanie zmodyfikowany po wykonaniu migawki, stara wersja pliku (taka, której można się spodziewać w migawce) jest przenoszona do obszaru woluminu migawki. W ten sposób wolumin migawki zawiera tylko kopie danych, które zostały zmodyfikowane od momentu powstania migawki.
Wolumen migawki można zamontować jako zwykły system plików. Jeśli użytkownik spróbuje uzyskać dostęp do pliku za pośrednictwem migawki, LVM sprawdzi, czy od momentu powstania migawki plik został zmodyfikowany. Jeśli nie, plik jest pobierany z oryginalnego systemu plików. Jeśli plik został zmodyfikowany, zamiast tego pobierana jest wersja z obszaru migawki.
W rezultacie wolumin migawki nie musi być tak duży jak wolumin oryginalny, ponieważ zawiera tylko zmiany, które zaistniały od chwili utworzenia migawki aż do teraz. Korzystanie z małego woluminu migawki wiąże się jednak z ryzykiem: jeśli oryginał zostanie zmodyfikowany w takim stopniu, że zmiany będą większe niż wolumin migawki, wolumin migawki zostanie usunięty i oznaczony jako uszkodzony. Dlatego ważne jest przydzielenie wystarczającej ilości miejsca na wolumin migawki.
Nie każdy system plików nadaje się do użycia w połączeniu z migawkami LVM. Systemy plików muszą obsługiwać zamrażanie, aby zagwarantować, że powstałe migawki będą w spójnym stanie podczas ich wykonywania. Wiadomo, że XFS i ext4 dobrze sprawdzają się w tej roli, ale opcji jest więcej [2].

Panaceum nie istnieje
Migawki nie są pozbawione wad. Główną wadą, jak wspomniano wcześniej, jest to, że korzystanie z nich wymaga starannego planowania. Jeśli zamierzamy używać migawek jako części strategii tworzenia kopii zapasowych danego folderu, to od początku musimy przechowywać zawartość tego folderu w pamięci masowej z funkcją migawek.
Kolejną kwestią jest wydajność: LVM jest znany z obniżania wydajności, gdy musi przechowywać wiele migawek wykonanych z tego samego systemu plików [3].
Największym problemem migawek LVM jest jednak to, że ich żywotność jest ograniczona. Migawki LVM śledzą zmiany dokonane w oryginalnym systemie plików (patrz ramka „Jak działają migawki LVM?”). Jeśli w oryginalnym systemie plików zostanie wprowadzona odpowiednio duża liczba zmian, w migawce LVM zabraknie miejsca na ich zarejestrowanie. Współczesny LVM obsługuje dynamiczne rozszerzanie woluminu migawki, jeśli wykryje, że kończy się mu miejsce [4], ale miejsce na dysku twardym jest ograniczone i migawka może zostać porzucona, jeśli będzie musiała przekroczyć pojemność fizycznej pamięci masowej.
Warto zauważyć, że wiele aplikacji nie gwarantuje spójności swoich plików podczas działania aplikacji. Na przykład zajęta baza danych może działać asynchronicznie, przechowując wiele operacji w pamięci podręcznej RAM i okresowo umieszczając je na dysku. Utworzenie kopii zapasowej doskonale odzwierciedlającej system plików, w którym przechowywana jest baza danych, spowoduje utworzenie kopii z niespójnymi danymi, ponieważ wiele operacji bazy danych mogło nie zostać zapisanych na dysku. Należy więc sprawdzić dokumentację programów, których kopie zapasowe tworzymy, aby poznać potencjalne pułapki.
Podsumowanie
Klasyczne narzędzia uniksowe nie są zalecane do tworzenia kopii zapasowych plików i katalogów, które są modyfikowane w trakcie tego procesu, ponieważ może to spowodować uszkodzenie kopii zapasowej. W tym artykule omówiliśmy LVM jako bezpieczniejszą alternatywę dla Linuksa, ale istnieją też inne narzędzia, które poradzą sobie z tym zadaniem, w tym migawki ZFS i BTRFS.
Wiele programów, zwłaszcza usług przeznaczonych do uruchamiania na serwerach produkcyjnych, produkcji, proponuje własne sposoby tworzenia kopii zapasowych (Rysunek 4). Bazy danych są znane z tego, że zawierają własne narzędzia do tworzenia kopii zapasowych, więc jeśli rzeczywiście używamy prawdziwej bazy danych (takiej jak MariaDB lub PostgreSQL), powinniśmy rozważyć użycie dostarczanych wraz z nimi narzędzi zamiast programów do tworzenia kopii zapasowych, które działają na poziomie systemu plików lub urządzenia blokowego.
Źródła:
[1] Antonios Christofides, Is Dump really Deprecated? (Czy Dump jest naprawdę przestarzały?): https://dump.sourceforge.io/isdumpdeprecated.html#canusedump
[2] Obsługa zamrażania dla wielu systemów plików: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=c4be0c1dc4cdc37b175579be1460f15ac6495e9a
[3] John Leach, LVM Snapshot Performance (Wydajność migawek LVM): https://johnleach.co.uk/posts/2010/06/18/lvm-snapshot-performance/
[4] Łata na LVM: https://listman.redhat.com/archives/lvm-devel/2010-October/msg00010.html

