

Potoki są zaskakująco wszechstronnym mechanizmem oferującym wiele możliwości, w tym przesyłanie danych między komputerami.
Wielu użytkownikom potoki kojarzą się z połączeniami między wieloma poleceniami (grep, less, sort, wc), jest to jednak ułamek ich możliwości. Potoki mogą pomóc w przesyłaniu danych – również między dwoma różnymi komputerami. W tym artykule pokażemy, jak efektywnie korzystać z potoków do przekierowywania strumieni danych w powłoce.
Kanały
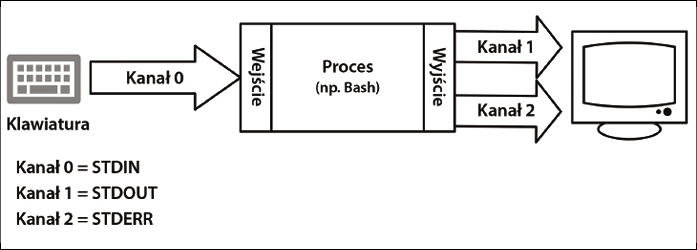
Za każdym razem, gdy w Linuksie uruchamiany jest jakiś proces, są mu automatycznie przypisywane trzy kanały. Te kanały mają przypisania systemowe, które umożliwiają ich adresowanie, przy czym każdy z nich ma punkt początkowy i końcowy. Kanał 0 (STDIN) odczytuje dane, kanał 1 (STDOUT) wyświetla dane, zaś kanał 2 (STDERR) wyświetla wszelkie komunikaty o błędach. Kanał 2 zazwyczaj wskazuje na to samo urządzenie co kanał 1 (Rysunek 1).
Listing 1: Przekierowywanie kanału
01 # ls -ld /dev/pseudo
02 ls: cannot access /dev/pseudo: No such file or directory
03 # echo $?
04 2
05 # ls -ld /dev/pseudo 2>/dev/null
06 # echo $?
07 2
Listing 2: Tworzenie nazwanego potoku
01 $ mkfifo /var/tmp/testpipe
02 $ ls -l /var/tmp/testpipe
03 prw-r--r-- 1 root root 0 Jan 4 23:35 /var/tmp/testpipe
Listing 3: Korzystanie z nazwanych potoków
### Sesja 1: Zapis
$ echo "3.1415" >/var/tmp/testpipe
### Sesja 2: Odczyt
$ ls -l /var/tmp/testpipe
prw-r--r- 1 root root 0 Jan 4 23:35 /var/tmp/testpipe
$ pi=$(cat /var/tmp/testpipe)
$ ls -l /var/tmp/testpipe
prw-r--r- 1 root root 0 Jan 4 23:42 /var/tmp/testpipe
$ echo $pi
3.1415
Listing 4: Definiowanie zmiennych
# started=$(date +'%H:%M:%S') ; echo $started
# ended=$(date +'%H:%M:%S'); echo $ended
23:04:44
23:04:44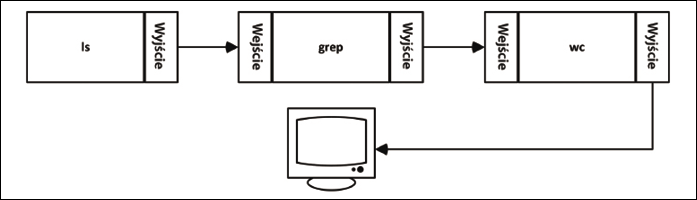
Sama powłoka także jest procesem uniksowym, zatem również używa tych trzech kanałów. Każdy z nich może być adresowany za pomocą deskryptora pliku reprezentującego odpowiedni numer kanału. W Linuksie używane tutaj kanały fizycznie znajdują się w katalogu /proc/PID/fd, gdzie PID jest odpowiednikiem identyfikatora danego procesu.
Najczęściej używana w Linuksie powłoka Bash ma również kanał 255. Aby zadbać o to, by podczas przekierowywania tego kanału kontrola zadań została zachowana, podczas uruchamiania powłoka ustawia go na STDERR.
Przekierowanie
Przekierowanie polega na odczycie kanałów procesu z innego źródła lub przesyłaniu danych w inne miejsce. Najczęstsze przypadki użycia tego mechanizmu to np. wyszukiwanie określonego ciągu w kanale STDERR i przekierowanie komunikatów o błędach do urządzenia /dev/null.
Wywołanie w wierszu 1 z Listingu 1 próbuje wyświetlić nieistniejący katalog /dev/pseudo/, co generuje komunikat o błędzie na kanale 2. Wywołanie z wiersza 5 dodaje do polecenia przekierowanie z kanału 2 do /dev/null. Komunikat o błędzie nie pojawi się już na ekranie, lecz wartość zwracana przez polecenie pozostaje niezmieniona.
Listing 5: Odczyt danych z potoku
### Terminal 1:
$ started=`date +'%H:%M:%S'` ; echo $start >/var/tmp/testpipe ; ende=`date +'%H:%M:%S'` ; echo $ended >/var/tmp/testpipe
### Terminal 2:
$ read started
Start: 23:08:40
End: 23:08:52Potoki
Potok jest specjalnym rodzajem pliku, który działa jako pamięć FIFO (to, co wchodzi jako pierwsze, wychodzi także jako pierwsze) w komunikacji międzyprocesowej. Dzięki FIFO jeden proces zapisuje do potoku, podczas gdy inny z niego odczytuje. Proces czytania pobiera znaki w tej samej kolejności, w jakiej zapisał je proces pisania. Jeśli np. proces 1 zapisuje w potoku wartości 1 Z 2 Y 3 X 4 W 5 V, proces 2 odczytuje je z potoku w tej samej kolejności. Linux używa dwóch typów potoków: potoków anonimowych i nazwanych.
Potoki anonimowe łączą polecenia za pomocą symbolu potoku (|). Potoki te są nazywane anonimowymi, ponieważ w normalnych warunkach użytkownik nie widzi ich w czasie działania. Potoki anonimowe, podobnie jak kanały standardowe, znajdują się w katalogu /proc/PID/fd/. Wywołanie sekwencji poleceń tymczasowo generuje ten rodzaj potoku.
Nazwane potoki można tworzyć w systemie plików za pomocą polecenia mkfifo. Pozostają aktywne do momentu ponownego usunięcia za pomocą polecenia rm. Kiedy używamy nazwanych potoków, musimy sami zadbać o przekierowanie, podczas gdy w przypadku potoków anonimowych powłoka robi to automatycznie.
Listing 6: Zdalne sterowanie
01 $ ssh [-q] HOST "polecenie1 [; polecenie2 [;...]]"
02 $ rcmd "polecenie1 [; polecenie2 [;...]]"Korzystanie z potoków
Doświadczeni użytkownicy Linuksa są prawdopodobnie zaznajomieni z potokami. Poniższy przykład wyszukuje wszystkie podkatalogi katalogu, w którym wywoływane jest polecenie, i zlicza je:
$
ls -l | grep "^d" | wc-l
138Dane wyjściowe z wywołania ls są kierowane do kanału wejściowego polecenia grep, podczas gdy dane wyjściowe z Grepa są kierowane do danych wejściowych polecenia wc (Rysunek 2).
Sposób działania przekierowania potoków anonimowych jest definiowany przez powłokę i zawsze działa od lewej do prawej. Po zakończeniu sekwencji poleceń wszystkie procesy kończą działanie, a przekierowania są usuwane.
W przypadku niektórych poleceń i skryptów możemy potrzebować potoków przez dłuższy czas lub dla większej liczby procesów – w takich przypadkach można użyć nazwanego potoku. Nazwane potoki znajdują się w systemie plików, podobnie jak inne pliki, i nie są usuwane po ponownym uruchomieniu systemu. Nazwane potoki mogą być używane przez wiele procesów, przy czym nie ma ograniczeń dotyczących odczytu lub zapisu przepływu danych.
Potoki nazwane
Aby utworzyć stały potok, możemy użyć polecenia mkfifo. Przykład pokazany na Listingu 2 utworzy potok o nazwie /var/tmp/testpipe. Polecenie ls pokazuje, że utworzenie potoku powiodło się. W danych wyjściowych z ls (wiersz 3) flaga p po lewej stronie informuje nas, że dany plik jest potokiem. Możemy teraz przekierować wyjście dowolnego polecenia do tego potoku. Polecenie to nie zakończy działania, dopóki inny proces nie odczyta danych z potoku (Listing 3).
Listing 7: Skrypt functions
001 setenv() {
002 # Ustaw wymagane zmienne środowiskowe
003 awkfile=/var/tmp/read.awk
004 BASENAME=${BASENAME:=/usr/bin/basename}
005 PYTHON=${PYTHON:=/usr/bin/python}
006 AWK=${AWK:=/usr/bin/awk}
007 TAR=${TAR:=/usr/bin/tar}
008 MKFIFO=${MKFIFO:=/usr/bin/mkfifo}
009 UNAME=${UNAME:=/usr/bin/uname}
010 TAIL=${TAIL:=/usr/bin/tail}
011 CAT=${CAT:=/usr/bin/cat}
012 SSH=${SSH:=/usr/bin/ssh}
013 NOHUP=${NOHUP:=/usr/bin/nohup}
014 RM=/usr/bin/rm
015 rhost=${REMOTEHOST:=localhost}
016 lhost=${LOCALHOST:=`$UNAME -n`}
017 sendpipe=/tmp/send.${rhost}
018 receivepipe=/tmp/receive.${rhost}
019 rsendpipe=/tmp/send.${lhost}
020 rreceivepipe=/tmp/receive.${lhost}
021 }
022
023 chkpipes() {
024 # Sprawdź, czy istnieją wymagane potoki
025 for pipe in $sendpipe $receivepipe
026 do
027 if [ ! -p $pipe ]
028 then
029 echo "cannot communicate with $rhost" >&2
030 return 1
031 fi
032 done
033 return 0
034 }
035
036 createpipes() {
037 # Wygeneruj wymagane potoki
038 setenv
039 for pipe in $sendpipe $receivepipe
040 do
041 if [ ! -p ${pipe} ]
042 then
043 $MKFIFO ${pipe}
044 if [ $? -ne 0 ]
045 then
046 echo "Cannot create ${pipe}" >&2
047 return 1
048 fi
049 else
050 echo "Pipe ${pipe} already exists"
051 fi
052 done
053 return 0
054 }
055
056 removepipes() {
057 # Można już usunąć potoki
058 setenv
059 for pipe in $sendpipe $receivepipe
060 do
061 if [ -p ${pipe} ]
062 then
063 rm -f ${pipe}
064 if [ $? -ne 0 ]
065 then
066 echo "Cannot remove ${pipe}" >&2
067 return 1
068 fi
069 else
070 echo "Pipe ${pipe} does not exist"
071 fi
072 done
073 return 0
074 }
075
076 listen() {
077 setenv
078 chkpipes # Czy wymagane potoki istnieją?
079 if [ $? -ne 0 ]
080 then
081 return 1
082 fi
083 # If present delete file with last directory used
084 if [ -w /tmp/lastpwd.${rhost} ]
085 then
086 $RM /tmp/lastpwd.${rhost}
087 fi
088 ( while read line
089 do
090 set $line
091 if [ "$1" = "BEGIN_CMD" ]
092 then
093 shift
094 # Uruchom polecenie
095 # Przejdź do ostatniego katalogu
096 if [ -r /tmp/lastpwd.${rhost} ]
097 then
098 cdircmd="cd `$CAT /tmp/lastpwd.${rhost}` ; "
099 else
100 cdircmd=""
101 fi
102 # Przekieruj wyjście do strumienia danych do wysłania
103 echo "BEGIN_CMD_OUT" >$sendpipe
104 echo "${cdircmd} $@" |/bin/bash >$sendpipe
105 echo "END_CMD_OUT" >$sendpipe
106 elif [ "$1" = "END_COMMUNICATION" ]
107 then
108 # Zakończ proces, jeśli odebrany zostanie ciąg END_COMMUNICATION
109 exit 0
110 elif [ "$1" = "BEGIN_FILETRANSFER" ]
111 then
112 # Jeśli ma zostać odebrany plik
113 filename=`$BASENAME $2`
114 tdir=$3
115 echo "Receiving file $filename..."
116 echo "Copying to $tdir..."
117 # Użyj Awka, aby czytać wiersze, dopóki nie zostanie odebrany
118 # ciąg END_FILETRANSFER
119 $AWK '
120 {
121 if ( $0 == "END_FILETRANSFER" )
122 exit 0
123 else
124 print $0
125 # Odebrane linie są dekodowane i przekierowywane do żądanego pliku docelowego
126 }' $receivepipe | $PYTHON -c 'import sys,uu; uu.decode(sys.stdin, sys.stdout)' >${tdir}/$filename
127 echo "File $filename transferred"
128 elif [ "$1" = "BEGIN_CMD_OUT" ]
129 then
130 # Jeśli odebrany zostanie ciąg BEGIN_CMD_OUT, wypisz wszystkie dalsze wiersze,
131 # aż do odebrania END_CMD_OUT
132 $AWK '
133 {
134 if ( $0 == "END_CMD_OUT" )
135 exit 0
136 else
137 print $0
138 }' $receivepipe
139 fi
140 done <$receivepipe
141 ) &
142 }
143
144 establish() {
145 setenv
146 chkpipes # Czy istnieją wymagane potoki?
147 # Czy istnieje plik Awka?
148 if [ ! -r $awkfile ]
149 then
150 echo "Cannot find $awkfile" >&2
151 return 1
152 fi
153 if [ $? -eq 0 ]
154 then
155 ( $TAIL -f $sendpipe | ( $SSH -q ${rhost} "$AWK -v pipe=${rreceivepipe} -f ${awkfile}" ) ) &
156 else
157 # Jeśli potoki nie istnieją, zamknij wyjście i funkcję
158 echo "Pipes for communication not present" >&2
159 return 1
160 fi
161 }
162
163 killall() {
164 # Wyślij wszystkich procesom komunikat o zakończeniu komunikacji
165 setenv
166 if [ -w $sendpipe ]
167 then
168 echo "END_COMMUNICATION" >$sendpipe
169 echo "." >$sendpipe
170 $RM -f /tmp/sendpipe_${rhost}.pid
171 fi
172 if [ -w $receivepipe ]
173 then
174 echo "END_COMMUNICATION" >$receivepipe
175 $RM -f /tmp/listener_${rhost}.pid
176 fi
177 }
178
179 rcmd() {
180 setenv
181 # Sprawdź, czy istnieje połączenie z REMOTEHOST
182 chkpipes
183 if [ $? -ne 0 ]
184 then
185 return 1
186 fi
187 # Wyślij przetworzony wiersz
188 echo "BEGIN_CMD $@ ; { pwd >/tmp/lastpwd.$lhost ;}" >$sendpipe
189 return $?
190 }
191
192 sendfile() {
193 setenv
194 # Sprawdź, czy można uruchomić Pythona
195 if [ -x $PYTHON -a ! -d $PYTHON ]
196 then
197 # Jeśli Python nie jest dostępny, zgłoś ten fakt i zakończ funkcję
198 if [ $# -lt 1 -o $# -gt 2 ]
199 then
200 echo "usage: sendfile FILE [target directory]"
201 return 1
202 fi
203 # Domyślnie skopiuj pliki do /var/tmp
204 tdir=${REMOTETEMPDIR:=/var/tmp}
205 if [ $# -eq 1 ]
206 then
207 file=$1
208 else
209 file=$1
210 tdir=$2
211 fi
212 # Zarejestruj i skopiuj plik
213 echo "BEGIN_FILETRANSFER $file $tdir" >$sendpipe
214 cat $file |$PYTHON -c 'import sys,uu; uu.encode(sys.stdin, sys.stdout)' >$sendpipe
215 echo "END_FILETRANSFER" >$sendpipe
216 else
217 echo "No python executable found. File transfer not possible." >&2
218 return 1
219 fi
220 }Jak widać, po odczycie połączenie zmieniło znacznik czasu z 23:35 na 23:42. Jednak rozmiar pliku nadal wynosi zero bajtów, ponieważ potok teoretycznie tylko przesyła dane. W rzeczywistości jednak system operacyjny zapewnia pewien bufor, choć z punktu widzenia użytkownika zazwyczaj nie jest to istotne.
Prosty przykład (pokazany na Listingach 4 i 5) jasno pokazuje, że – z perspektywy procesów – zapis do potoku rozpoczyna się dopiero wtedy, gdy potok jest odczytywany. W tej sesji polecenie zapisuje bieżącą datę i godzinę w zmiennej start, a następnie zapisuje zawartość zmiennej w potoku. Następnie ponownie odczytuje datę i godzinę i zapisuje wartości w zmiennej end. Proces również natychmiast zapisuje swoją wartość do potoku. Druga sesja odczytuje oba wiersze z potoku i wyświetla je.
Aby pokazać, że dane wyjściowe są faktycznie generowane w krótkim czasie, pierwsze uruchomienie nie używa przekierowania (Listing 4). Teraz dwóm zmiennym ponownie przypisywane są znaczniki czasu, a dane wyjściowe są w każdym przypadku zapisywane w potoku. Krótko po tym potok jest odczytywany wiersz po wierszu w drugiej sesji, a wyniki są wyświetlane na ekranie (Listing 5). Widać, że między początkiem a końcem jest różnica kilku sekund. Różnica wynika z faktu, że drugi znacznik czasu jest tworzony dopiero po odczytaniu pierwszego wiersza z potoku.
Przykładowa aplikacja
Na Listingu 6 widzimy prosty schemat połączenia sieciowego opartego na nazwanych potokach używanego do wykonywania poleceń na komputerze zdalnym.
Interesującym aspektem komunikacji między dwoma komputerami jest to, że dla procesu przeprowadzającego odczyt lub zapis nie ma znaczenia, co dzieje się przed potokiem lub po nim, ponieważ nie ma to wpływu na odczyt i zapis. Listing 6 zakłada, że komunikacja między dwoma komputerami nie jest chroniona hasłem i w tym przykładzie opiera się na protokole SSH.
Polecenie ssh pozwala określić zarówno łańcuch poleceń, jak i komputer docelowy (wiersz 1, Listing 6). SSH łączy się teraz z systemem docelowym, wykonuje określone polecenia, a następnie kończy połączenie. Prościej byłoby wywołać funkcję, która następnie otrzymuje polecenie do wykonania, uruchamia ją na drugiej maszynie i wyświetla dane wyjściowe na lokalnym ekranie (wiersz 2).
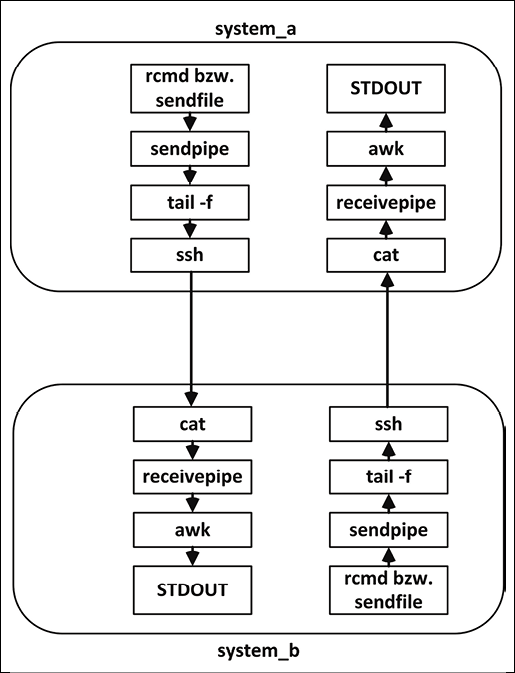
Funkcja rmcd pochodzi ze skryptu functions (Listing 7). Każdy komputer używa jednego potoku do wysyłania i jednego potoku do odbierania. Proces stale odczytuje potok wysyłający i przekierowuje odczytane wiersze do strumienia danych. W tym przykładzie SSH wysyła strumień danych do komputera zdalnego. Po stronie odbierającej przychodzący strumień danych jest przekierowywany do potoku odbierającego, w którym jest odczytywany. Potok przetwarza odczytane dane i zapisuje wyniki do potoku wysyłającego, by przesłać wyniki z powrotem do komputera źródłowego (Rysunek 3).
Komunikacja w rysunku 3 jest rozbita na kilka segmentów. Zasadniczo chodzi o odbieranie danych za pośrednictwem strumienia danych, przetwarzanie danych i odesłanie strumienia danych w odpowiedzi. Ale jak utrzymać ciągły strumień danych między dwoma komputerami w celu wysyłania poleceń i innych informacji?
Nasłuchiwanie
Polecenie tail -f kończy działanie, kiedy napotka koniec pliku (EOF) – ale tylko w przypadku zwykłego pliku. Jeśli argumentem jest deskryptor pliku, na którym nie można przeprowadzić operacji seek(), tail -f zakończy działanie po napotkaniu EOF. Nadaje się więc do odczytu danych, jednak nie można po prostu przekierować pojedynczego polecenia, ponieważ EOF pojawia się po przetworzeniu polecenia. Użycie pliku tekstowego do transportu również nie zadziała, ponieważ lokalizacja danych ciągle się zmienia, więc polecenie tail nie będzie mogło odczytać prawidłowych informacji.
Możemy to przetestować, uruchamiając tail -f na pustym pliku w jednej sesji i przekierowując dane wyjściowe wybranego polecenia do tego pliku w drugiej sesji: ujrzymy komunikat file truncated (plik obcięty). Moglibyśmy co prawda dodać do pliku tekstowego wszystkie informacje do przetworzenia przez maszynę zdalną, ale spowodowałoby to niepotrzebne zużycie pamięci.
Rozwiązaniem są nazwane potoki. Ponieważ proces zapisuje dane do potoku tylko wtedy, gdy zdalna maszyna odczytuje dane w tym samym czasie, proces nie wymaga dodatkowej pamięci dla potoku — polecenie tail zawsze odczytuje dane z potoku w tym samym momencie. Aby nawiązać komunikację między dwoma komputerami, potrzebne są dwa nazwane potoki. Pierwszy odbiera strumień danych ze zdalnego komputera, a drugi wysyła przetworzone dane do systemu docelowego.
Dane wyjściowe z tail -f opierają się na anonimowym potoku dostarczającym strumień danych. Następnie przekierowujemy go do sesji SSH, która zapisuje dane w potoku odbierającym na zdalnym komputerze. Ta konfiguracja może zostać zaimplementowana za pomocą wywołania pokazanego na Listingu 8.
Kolejnym krokiem jest określenie formatu, w jakim dane docierają do systemu docelowego. Stosunkowo prosta opcja polega na zdefiniowaniu funkcji osadzającej polecenia do wykonania w odpowiedniej kolejności. Robi to funkcja rcmd z listingu 6 (wiersz 2); wystarczy jej przekazać jako argument polecenie, które chcemy wykonać.
Aby system docelowy mógł zrozumieć, co powinno się stać z otrzymanymi danymi, przesyłanie rozpoczyna się od znacznika tekstowego BEGIN_CMD, po którym następuje polecenie do wykonania. Po otrzymaniu jednego wiersza system docelowy sprawdza, jaki łańcuch zawiera pierwszy argument. Jeśli jest to BEGIN_CMD, system docelowy przekierowuje drugi argument do powłoki. Ta z kolei przekierowuje wynik do potoku i odsyła go z powrotem do nadawcy.
Zaletą tej metody jest to, że polecenie nie musi być przetwarzane w programie. Na listingu 9 ciąg jest zapisywany w podpowłoce, która następnie wykonuje polecenia i wyświetla wynik na ekranie. Odpowiedź wynikowa pojawia się na komputerze zdalnym.
Jeśli chcemy uruchomić wiele poleceń na systemie docelowym, ale nie w domyślnym katalogu tego systemu, możemy otworzyć podpowłokę dla każdego polecenia, co oznacza, że każde polecenie działa również w identycznym środowisku (Listing 10). Jak widać, katalog docelowy /root jest ważny tylko do momentu przetworzenia sekwencji poleceń. Drugi przebieg wyświetla bieżący katalog roboczy procesu nadrzędnego.
Aby obejść ten problem w przypadku komunikacji między dwoma systemami, system docelowy otrzymuje zarówno właściwe polecenie, jak i instrukcje odnośnie zapisania bieżącego katalogu roboczego w tymczasowym pliku tekstowym. Przy następnym wykonaniu polecenia proces sprawdza, czy istnieje plik tymczasowy, a w razie potrzeby analizuje go i ustawia odpowiedni katalog (Listing 11).
No dobrze, ale zależy nam nie tylko na wykonywaniu poleceń na zdalnym komputerze – chcemy również przesyłać pliki. W tym celu musimy pokonać jeszcze jedną przeszkodę. Nie możemy bowiem wyświetlić wiersza o dowolnej długości za pomocą echo. Aby zapobiec potencjalnemu zinterpretowaniu przez komputer zdalny znaków, które wysyłamy jako znaki sterujące, musimy również przekonwertować dane binarne na zwykły kod ASCII.
We wcześniejszych wariantach Uniksa istniało polecenie uuencode i jego odpowiednik uudecode. Ponieważ te polecenia są dziś rzadko używane i nie są instalowane domyślnie w większości dystrybucji, najbezpieczniej jest użyć modułu Pythona, aby zapobiec błędnej interpretacji znaków.
Tabela 1: Przegląd funkcji
| Funkcja | Opis |
| setenv | Ustawia wszystkie wymagane zmienne środowiskowe. |
| chkpipes | Sprawdza, czy wymagane potoki istnieją w /tmp |
| createpipes | Generuje wszystkie wymagane potoki w /tmp |
| removepipes | Usuwa wszystkie potoki na zdalnym hoście |
| listen | Generuje detektor, który odczytuje i przetwarza pliki przychodzące |
| establish | Generuje strumień danych w kierunku drugiego komputera |
| killall | Kończy wszystkie wymagane procesy w tle |
| rcmd | Uruchamia polecenie na zdalnym hoście |
| sendfile | Kopiuje plik do systemu zdalnego |
Listing 8: Generowanie strumienia danych
$ tail -f Send-Pipe | ssh -q HOST "cat > POTOK-ODBIORCZY"
Listing 9: Wyświetlanie wyników
$ echo "cd /var/tmp; ls -l | wc -l" | /bin/bash
29
Listing 10: Ścieżka środowiska roboczego
# echo "cd /root ; pwd" | /bin/bash
/root
echo "pwd"| /bin/bash
/var/tmpPrzepływ programu
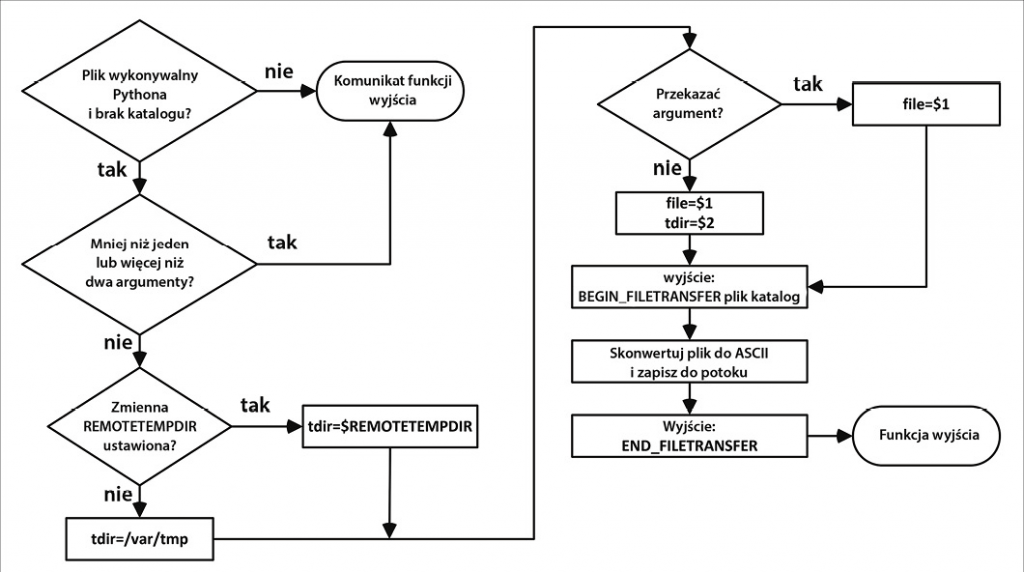
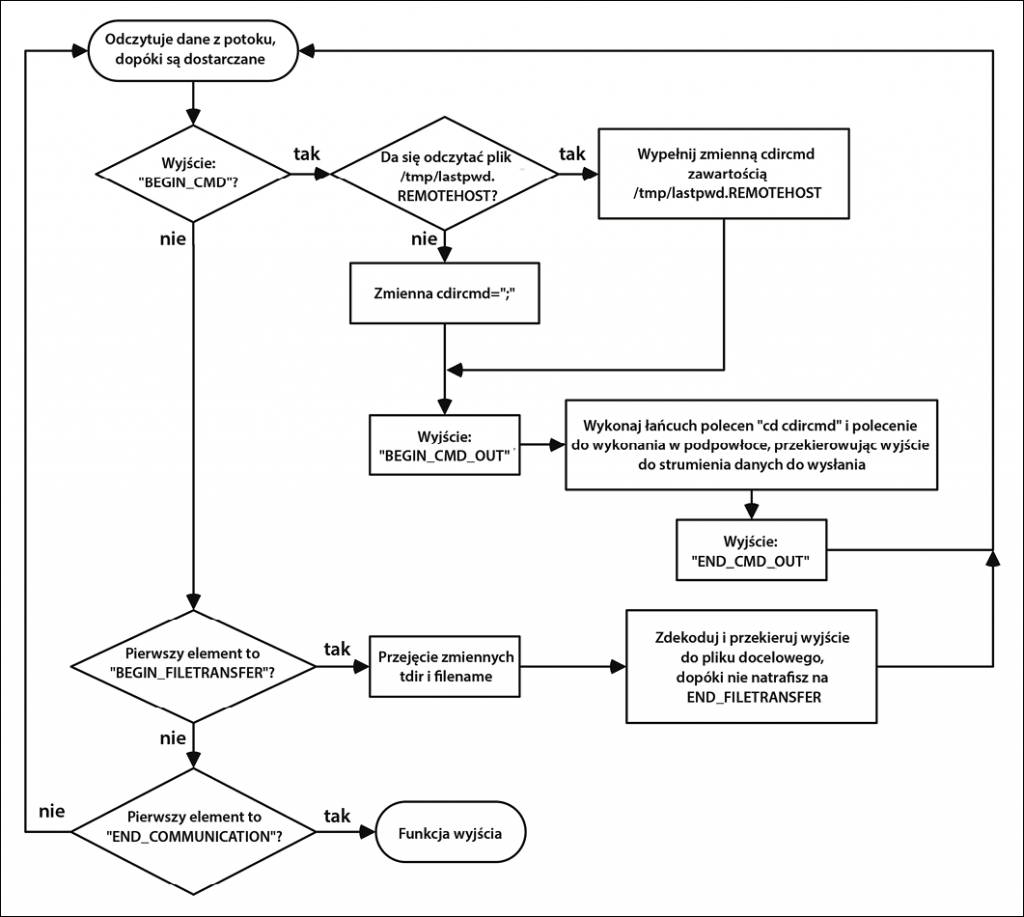
Komputer docelowy odczytuje potok odbiorczy i inicjuje odpowiednie czynności. Jeśli otrzyma wiersz zawierający polecenie do wykonania, najpierw sprawdza, czy istnieje plik tekstowy zawierający ostatni katalog roboczy (Rysunek 4). W następnym kroku zapisuje ciąg BEGIN_CMD_OUT w wychodzącym strumieniu danych.
Po przesłaniu proces przechodzi do żądanego katalogu i zapisuje polecenia do wykonania w podpowłoce. Dane wyjściowe polecenia są zapisywane w przesyłanym strumieniu danych. Koniec polecenia jest oznaczony ciągiem END_CMD_OUT. Jeśli otrzymany wiersz zaczyna się od ciągu END_COMMUNICATION, proces zostaje zakończony.
Jeśli transfer rozpoczyna się od BEGIN_FILETRANSFER, funkcja odczytuje argumenty 2 (nazwa pliku) i 3 (katalog docelowy). Używając Awka, skrypt przesyła dane do modułu Pythona, który zajmie się dekodowaniem danych, dopóki nie otrzyma wiersza END_FILETRANSFER.
Na koniec funkcja sprawdza, czy otrzymany wiersz zawiera ciąg BEGIN_CMD_OUT. Jeśli tak, wyświetla wszystkie pozostałe wiersze na ekranie, dopóki nie otrzyma ciągu END_CMD_OUT. Rysunek 5 przedstawia schemat blokowy systemu nasłuchującego.
Możliwości rozbudowy
Tabela 1 zawiera podsumowanie wszystkich funkcji zawartych w skrypcie functions (Listing 7). Zwróćmy uwagę, skrypt ten ilustruje tylko ułamek możliwości oferowanych przez nazwane potoki.
Nasz skrypt ma kilka drobnych wad. Po pierwsze, funkcji killall z Listingu 7 nie zawsze udaje się za pierwszym razem zakończyć wszystkie procesy. Jeśli napotkamy na ten problem, musimy wywołać ją ponownie. Ponadto podczas uruchamiania programu nasłuchującego skrypt z Listingu 7 nie sprawdza, czy inny proces może już odczytywać dane z potoków, co może prowadzić do błędów. Brakuje też funkcji, która przed skopiowaniem pliku sprawdziłaby, czy katalog docelowy istnieje. Jeśli lokalna nazwa hosta nie jest taka sama jak alias przypisanego adresu IP, wystąpi nieprawidłowość, ponieważ strona zdalna nie jest świadoma tego problemu. Wszystkie te problemy można stosunkowo łatwo rozwiązać, jednak znacznie zwiększyłoby to rozmiary listingu zamieszczonego w artykule.
Listing 11: Ustawienie właściwego katalogu
# type rcmd
rcmd is a function
rcmd ()
{
setenv;
chkpipes;
if [ $? -ne 0 ]; then
return 1;
fi;
echo "BEGIN_CMD $@ ; { pwd >/tmp/lastpwd.$lhost ;}" > $sendpipe;
return $?
}
Listing 12: read.awk
{
if ($0 != "END_COMMUNICATION") {
print $0 >pipe
fflush(pipe)
}
else {
close (pipe)
exit 0
}
}Możemy też oczywiście rozbudować skrypt o nowe funkcje. Można by np. rozważyć nawiązanie komunikacji między dowolną liczbą komputerów. Aby to zrobić, musimy przekazać maszynie zdalnej identyfikator nadawcy, aby w każdym przypadku zapisywała ona dane wyjściowe we właściwych potokach.
Sensowne byłoby również dodanie narzędzia do kompresji, aby przyspieszyć transmisję – odbiorca musiałby wtedy zdekompresować strumień danych. Inną interesującą możliwością byłoby przesłanie do nadawcy wartości zwrotnej wykonanego polecenia.
Zwróćmy uwagę, że plik read.awk (Listing 12) domyślnie powinien znajdować się w katalogu /var/tmp/. Jeśli znajduje się w innej lokalizacji, należy dostosować zmienną awkfile na listingu 7.
Podsumowanie
Potoki służą nie tylko do konstruowania długich łańcuchów poleceń, można ich również użyć jako interesującego narzędzia do komunikacji między wieloma procesami. Fakt, że system traktuje potoki jak normalne pliki daje nam nowe możliwości – zwłaszcza w połączeniu z możliwością przekierowywania kanałów. Przydatny jest też fakt, że potoki mogą być adresowane identycznie we wszystkich pochodnych Uniksa – w tym w Linuksie.

