

Istnieje wiele sposobów, by dowiedzieć się wielu interesujących rzeczy o komunikacji między przeglądarką internetową a serwerem HTTP. Jednym z najlepszych z nich jest zbudowanie własnego serwera WWW.
Napisanie własnego serwera WWW może się wydawać trudnym i niepotrzebnym przedsięwzięciem. Istnieje przecież mnóstwo takich serwerów, od popularnych i uniwersalnych, takich jak Apache lub Nginx, po lekkie alternatywy, takie jak Cherokee czy Lighttpd.
Czasem jednak nie potrzebujemy pełnego serwera WWW. Jeśli chcemy jedynie udostępnić kilka stron we własnej sieci lub zaoferować innym możliwość przesyłania plików, wystarczą narzędzia, które znajdziemy w praktycznie każdej dystrybucji, całością zaś może sterować prosty skrypt powłoki. Natomiast komunikacją sieciową może zająć się Netcat [1] – uniwersalne narzędzie do obsługi TCP i UDP.
Listing 1: Konfiguracja
HTTP_HOME=http_home
HTTP_UPLOAD=${HTTP_HOME}/upload
CACHE_DATEI=${HTTP_UPLOAD}/filetoprocess
FIFO_GET=fifo_get
HTTP_GET_PORT=8080
HTTP_POST_PORT=8081
MEINE_IP=$(ip addr show| grep -Eo "([0-9]{1,3}\.){3}[0-9]+" | sed 1q)Przygotowania
Przy takim projekcie najlepiej zacząć od samego początku. Ponieważ serwer WWW, jak sama nazwa wskazuje, jest serwerem, musi stale nasłuchiwać na danym porcie i odpowiednio reagować na żądania. Zazwyczaj serwery WWW nasłuchują na porcie 80, który zwykle używany jest do akceptacji żądań HTTP – bez szyfrowania. Serwer WWW, który opiszemy w niniejszym artykule, nasłuchuje na portach 8080 i 8081 i obsługuje komunikację HTTP bez szyfrowania. Jeśli używamy zapory sieciowej i chcemy przetestować działanie serwera w sieci lokalnej, pamiętajmy, aby otworzyć te dwa porty.
Serwer WWW potrzebuje folderu głównego, z którego będzie ładował żądane pliki HTML. Potrzebuje również katalogu, w którym będzie mógł przechowywać przesłane pliki. Zatem pierwszym krokiem jest zdefiniowanie konfiguracji przy użyciu szeregu prostych zmiennych na początku skryptu serwera (Listing 1). Oczywiście musimy też utworzyć zdefiniowane katalogi (łącznie z plikiem FIFO), ręcznie lub za pomocą wbudowanego w Basha polecenia test (skrypt server6.sh dołączony do archiwum z listingami do niniejszego artykułu [2]).
Jak widzimy w ostatnim wierszu Listingu 1, ważny jest również nasz adres IP. Będziemy też musieli odpowiednio zmodyfikować nazwę urządzenia sieciowego (w tym przykładzie jest to interfejs ethernetowy enp2s0).
Kiedy przeglądarka internetowa próbuje pobrać plik HTML, potrzebuje adresu docelowego. W takiej sytuacji najprościej jest użyć żądania GET. Gdy przeglądarka wysyła żądanie GET, oczekuje w odpowiedzi zawartości strony internetowej i wyświetla tę zawartość w oknie przeglądarki.
Listing 2: Generowanie przykładowych plików HTML za pomocą skryptu
function create_files () {
for x in {1..7}; do
cat <<-FILE > ${HTTP_HOME}/datei${x}.html <html><head><meta charset="utf-8"> <title>Page ${x}</title>
</head><body>
<p> $( date ) </p>
<p> Page ${x} </p>
</body></html>
FILE
done
}Przykładowe pliki
Pliki do testowania serwera WWW można łatwo przygotować za pomocą skryptów. Przedstawiona na Listingu 2 funkcja siedmiokrotnie wykonuje pętlę for, wykorzystując mechanizm heredoc, by osadzić kod HTML niemal 1:1 (<<, trzecia linia), przy czym odwołujemy się do zmiennej ustawionej w instrukcji for, która następnie zawiera numer sekwencyjny.
Mechanizm heredoc istnieje w wielu językach programowania i pomaga definiować dłuższe bloki tekstu. W ten sposób – w przeciwieństwie do konwencjonalnego wyjścia za pomocą echo lub printf – w tekście zachowany jest podział na wiersze, wcięcia i niektóre znaki specjalne bez konieczności wstawiania dodatkowych sekwencji, takich jak \n. Bash obsługuje również użycie zmiennych w blokach heredoc.
W ten sposób możemy utworzyć tyle plików HTML, ile potrzebujemy, za pomocą kilku linijek kodu. Opcjonalnie można zintegrować dodatkowe treści generowane dynamicznie za pomocą skryptu.
Będziemy też musieli utworzyć kilka przykładowych plików HTML do testowania własnego serwera. (Patrz ramka „Przykładowe pliki”).
Żądania GET
Odpowiedź na żądanie GET to znacznie więcej niż samo przesłanie zawartości pliku: HTTP i HTTPS wymagają, by wraz z samą treścią przesłane zostały dodatkowe informacje. Jeśli chcemy się dowiedzieć, jak wygląda odpowiedź przesyłana przez prawdziwy serwer WWW, możemy użyć polecenia podobnego do poniższego:
wget --spider -S "https://devmasters.pl"Narzędzie wget działa w terminalu i pobiera podaną stronę internetową. Opcja –spider nakazuje Wgetowi, aby zachowywał się jak pająk sieciowy; innymi słowy, program nie pobiera żadnych treści, lecz jedynie sprawdza, czy dane zasoby istnieją, i otrzyma informacje o transmisji związane z żądaniem HTTP.
W pierwszym wierszu serwer potwierdza, że chętnie przyjmuje żądanie HTTP — HTTP/1.1 200 OK. Dalsze wiersze w postaci par wartości (takich jak Connection: keep-alive, Content-Length:300) służą do przekazywania dodatkowych informacji lub instrukcji.
Wiele serwerów WWW nie ujawnia dokładnie, na jakim oprogramowaniu działają. Jest to niewielkie utrudnienie dla włamywaczy, ponieważ istnieje wiele metod określenia rodzaju serwera WWW, ale automatycznie blokuje wiele prostych skryptów, które wyszukują starszych wersji serwerów ze znanymi błędami, i przypuszcza próby ataku – jest to nieszkodliwe, ale niepotrzebnie zużywa zasoby.
Tak czy inaczej, jeśli chcemy, aby Netcat zachowywał się jak prawdziwy serwer WWW, będziemy musieli wygenerować wszystkie niezbędne informacje, które muszą znaleźć się w nagłówku HTTP.
Netcat
Netcat jest dostępny na praktycznie każdej dystrybucji Linuksa i można go używać do wielu różnych celów, choć ma pewne ograniczenia. Za pomocą Netcata można emulować podstawowe operacje sieciowe, ale złożone interakcje są trudne do przeprowadzenia. Zdecydowanie nie chcemy za pomocą Netcata konkurować z Apache lub Nginksem.
Jeśli Netcat ma stale nasłuchiwać na porcie, a także wysyłać różne odpowiedzi, musimy połączyć go w pętlę z plikiem FIFO. Nazwa FIFO odnosi się do zasady „pierwszy na wejściu, pierwszy na wyjściu” czy też „pierwszy wszedł, pierwszy wychodzi” (od angielskiego First In, First Out). Oznacza to, że informacje wracają z pliku w tej samej kolejności, w jakiej zostały wysłane [3]. Przykład widzimy na Listingu 3.
Jak pokazano na Listingu 4, plik FIFO poprawia komunikację między Netcatem a funkcją respond: Netcat nasłuchuje na określonym porcie i zapisuje dane do pliku FIFO. Po lewej stronie potoku można zobaczyć wywołanie funkcji, która odczytuje żądanie przeglądarki. Skrypt analizuje żądanie, a następnie wysyła pasującą odpowiedź – zawierającą nagłówek HTML i dane HTML – za pośrednictwem potoku z powrotem do Netcata. Zatem to funkcja respond decyduje, co zwrócić do przeglądarki.
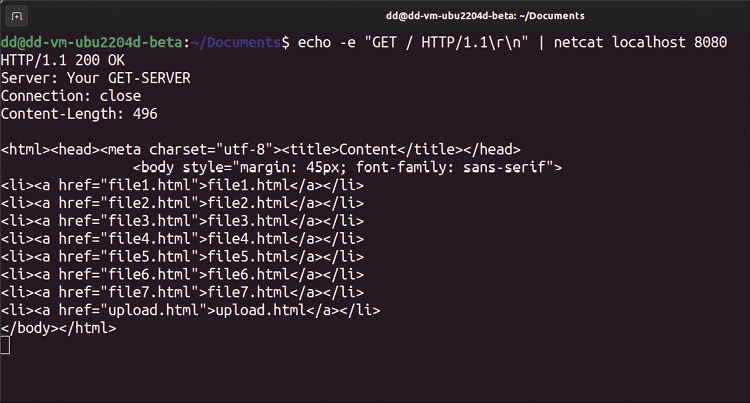
Bieżąca wersja jest już dość potężnym rozwiązaniem. Jeśli długość żądania przeglądarki to 1 (wiersz 3), chodzi o /, a wtedy Netcat zwraca listę katalogów. Jeśli długość nie jest równa 1, Netcat zwraca zawartość pliku z katalogu głównego. Aby serwer WWW zwrócił listę plików zawartych w folderze głównym, wystarczy bardzo proste polecenie – ls NAZWA_KATALOGU. Jednak wyniki muszą być osadzone w odpowiednim kodzie HTML, aby linki działały i przeglądarka mogła z nich korzystać (Rysunek 1). Do konwersji wykazu katalogów na kod HTML możemy użyć edytora strumieni Sed [4].
Listing 3: Odpowiedź Netcata
while true; do
respond < $FIFO_GET | netcat -l $HTTP_GET_PORT > $FIFO_GET
done
Listing 4: Plik FIFO
01 function respond () {
02 read get_or_post address httpversion
03 if [ ${#address} = 1 ]; then
04 list_dir
05 elif [ ${#address} -gt 1 ]; then
06 return_file $address
07 fi
08 }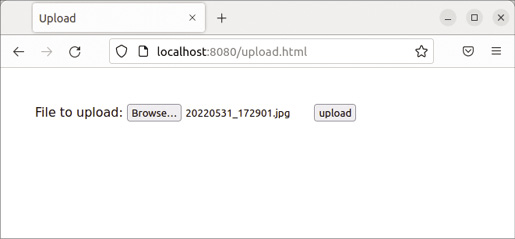
Listing 5: Generowanie danych wyjściowych
01 function list_dir () {
02 local out-put=$( ls --hide=upload -1 $HTTP_ HOME | sed -r '
03 1 i<html><head><meta charset="utf-8"><title>Content</title></head>\ 04 <body style="margin: 45px; fontfamily: sans-serif">
05 s#(.*)#<li><a href="\1">\1</a></li># 06 $ a</body></html>
07 ' )
08
09 local content_length="Content-Length: $( cat <<<$output | wc --bytes )"
10
11 cat <<<$output | sed '
12 1 i HTTP/1.1 200 OK
13 1 i Server: Your GET SERVER
14 1 i Connection: close
15 1 i '"$content_length"'\n
16 '
17 }
18
19 function return_file () {
20 content=$( cat ${HTTP_HOME}/${1:1} )
21 if [[ $? -eq 0 ]]; then
22 laenge=$( cat <<<${con-tent} | wc --bytes )
23 cat <<<${content} | sed -r '
24 1 i HTTP/1.1 200 OK
25 1 i Server: Your GET SERVER
26 1 i Connection: close
27 1 i Content-Length: '"$length"'\n'
28 else
29 cat <<-ERROR
30 HTTP/1.1 404 Not Found
31 Connection: close
32 Content-Length: 42
33
34 The requested page does not exist, sorry!
35 ERROR
36 fi
37 }Listing 5 przedstawia funkcje, do których odwołuje się Listing 4. W funkcji list_dir zawartość katalogu jest wyświetlana za pomocą prostego polecenia ls, po czym Sed konwertuje ją na zwykły HTML. Pliki wygenerowane przez funkcję z Listingu 2, które znajdują się w katalogu głównym, zawierają już kod HTML. W wierszu 19 z Listingu 5 serwer używa funkcji return_file, aby wysłać plik z powrotem do przeglądarki z odpowiednim nagłówkiem.
Ponieważ Netcat jest stale dostępny dla żądań w pętli i wysyła nagłówek oraz odpowiedni kod HTML, przeglądarka w sieci lokalnej potraktuje go jak prawdziwy serwer WWW.
Może się jednak również zdarzyć, że użytkownik ręcznie zażąda strony w przeglądarce, która nie istnieje. Prowadzi to do pojawienia się słynnego błędu 404, który zna każdy użytkownik sieci WWW [5]. Oczywiście tę funkcję możemy również łatwo zaimplementować. Jeśli polecenie cat w pierwszym wierszu funkcji return_file (wiersz 20) zgłosi błąd, zostanie wykonana gałąź else zaczynająca się od wiersza 28. Przeglądarka internetowa wyświetli wówczas komunikat, że żądana strona nie istnieje.
Żądania POST
W przeciwieństwie do żądań GET, w których przeglądarka internetowa chce pobrać pliki, istnieją również żądania POST, które umożliwiają przeglądarce wysyłanie danych do serwera WWW. Pomyślmy o publikowaniu czegoś w mediach społecznościowych. Wpisujemy tekst, dodajemy obrazki, a nawet filmy wideo w polu przeznaczonym do tego celu, po czym naciskamy Opublikuj. Następnie treść jest przesyłana na serwer i wyświetlana na naszym profilu. Nasz prosty serwer potrafi przesłać pliki z przeglądarki i zapisać je w folderze uploads/.
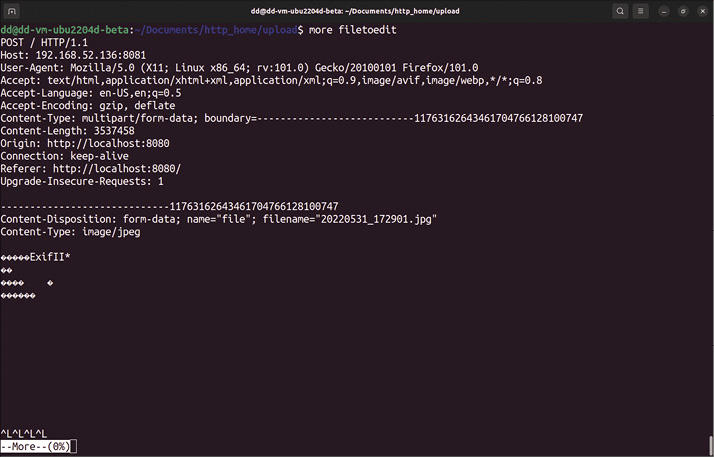
W tym przypadku przeglądarka wysyła nagłówek wskazujący, że chce coś opublikować. Możemy łatwo sprawdzić, jak wygląda żądanie POST, uruchamiając polecenie przedstawione na Listingu 6. W przeglądarce otwieramy znajdujący się w folderze głównym formularz i wysyłamy plik (Rysunek 2). Po kilku sekundach przerywamy działanie Netcata, naciskając Ctrl+C. Przeglądarka wyświetli komunikat File arrived, plik powinien zaś znaleźć się tam, gdzie został przekierowany. Przesłanego w ten sposób pliku JPEG nie da się jednak wyświetlić, ponieważ nadal zawiera nagłówek (Rysunek 3).
Na Listingu 7 widzimy, jak za pomocą Seda pozbyć się nadmiarowych danych. Sed obsługuje to zadanie w rozpoczynającej się w wierszu 9 pętli while, usuwając nagłówek, instrukcje graniczne, nazwę pliku i podobne dane. Gdyby Sed nie usunął całego tego balastu, system operacyjny nie mógłby poprawnie wyświetlić odebranych plików. W katalogu upload znajduje się też kopia oryginalnego pliku ze wszystkimi danymi – możemy łatwo porównać oba pliki, by zorientować się, co zostało usunięte.
W tle procedura wywołuje również funkcję run_post_server (wiersz 17). Zawiera ona odpowiedź na żądania POST określającą długość treści w bajtach i zawierającą instrukcje przerwania połączenia po odczytaniu. Bez tych instrukcji Firefox utrzymałby otwarte połączenie, mimo że dane zostały już wysłane. Funkcja uruchamia się w tle (&), by niczego nie blokować po przesłaniu plików.
Niezaznaczone
Nawet jeśli przeglądarka internetowa jawnie zażąda katalogu głównego lub innego pliku, zasadniczo serwer WWW może zwrócić to, co zechcemy – wystarczy poprawnie zadeklarować zwróconą zawartość, by przeglądarka mogła ją odpowiednio odczytać. Listing 8 pokazuje przykład, w którym przeglądarka wyświetla plik JPEG od razu po wywołaniu localhost:8080 lub IP_address:8080, nie zgłaszając żadnych komunikatów o błędach.
Dlaczego ta sztuczka w ogóle działa? Otóż wraz z upływem czasu przeglądarki zaczęły akceptować coraz więcej odstępstw od standardów, dzięki czemu użytkownicy napotykają mniej błędów. Wygląda na to, że większość przeglądarek internetowych nie zawraca sobie głowy sprawdzaniem, czy zawartość żądania GET i zwrócona strona rzeczywiście pasują. W tym przypadku przeglądarka poprosiła serwer WWW o stronę z indeksem, a zamiast tego otrzymała plik JPEG. To tak jakby tenisista w odpowiedzi na serw otrzymał od przeciwnika piłkę od koszykówki.
Listing 6: Symulacja POST
$ echo "File arrived" | netcat -l 8081 > upload/filex.jpg
Listing 7: Filtrowanie zbędnych danych
01 function run_post_server () {
02
03 message_for_post='HTTP/1.1 200 OK
04 Content-Length: 13
05 Connection: close
06
07 File arrived
08
09 while true; do
10 cat <<< $message_for_post | netcat -l $HTTP_POST_PORT > "${CACHE_DATEI}"
11 new_name=$( sed -r -n '/filename/{ s/(.*)(filename=")(.+)(".*)/\3/; p}' ${CACHE_DATEI} )
12 upload_path="${HTTP_UPLOAD}/${new_name}"
13 sed '1,/filename/d;/Content-Type/{N;d};$d' ${CACHE_DATEI} > "${upload_path}"
14 done
15 }
16
17 run_post_server &
Listing 8: Wysyłanie pliku JPEG
#!/bin/bash
header="HTTP/1.1 200 OK"
myfile="http_home/upload/IMG-20220213-WA0002.jpg"
content_length="Content-Length: $( cat $myfile | wc --bytes )"
content_type="Content-Type: image/jpeg"
cat $myfile | sed -r -e "1 i $header" -e \
"1 i $content_length" -e \
"1 i $content_type" -e \
"1 i Connection: close\n" | netcat -l 8080
Listing 9: Uruchomienie serwera WWW
function run_server () {
while true; do
date | sed -r 's/^|$/\n/g' >> debug
respond < $FIFO_GET | tee --append debug |
netcat -l $HTTP_GET_PORT |
tee --append debug > $FIFO_GET
done
}
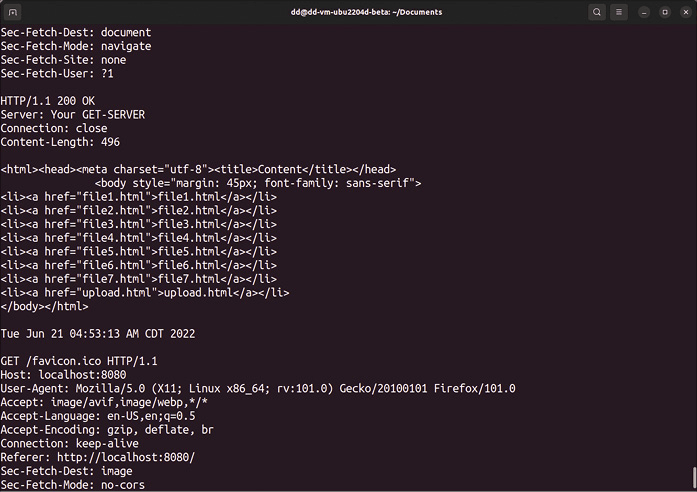
Z doświadczenia wynika, że RFC sobie, a praktyka sobie, dlatego przydatne może być rejestrowanie żądań Firefoksa i innych przeglądarek. Przedstawiona na Listingu 9 funkcja uruchamia serwer; możemy tam zobaczyć dwa przekierowania tee, które przekazują wszystkie dane do pliku dziennika. W ten sposób zarejestrujemy datę i godzinę każdego żądania przeglądarki i każdej odpowiedzi serwera (Rysunek 4). Dysponując tymi szczegółami, możemy przeanalizować każde żądanie i odpowiedź oraz zrozumieć, co dokładnie się dzieje, gdy klient i serwer rozmawiają ze sobą.
Na przykład wiele przeglądarek po krótkiej rozmowie z serwerem pyta o słynny plik favicon.ico. Jest to ikona, którą zwykle widzimy w lewym górnym rogu karty przeglądarki i która zwykle znajduje się w folderze głównym serwera WWW.
Jeśli chcemy, aby nasz serwer udostępniał favicon.ico, musimy najpierw dowiedzieć się, jak wygląda żądanie przeglądarki, a następnie powiedzieć serwerowi, aby odpowiednio na nie zareagował. Możemy stwierdzić, że przeglądarka internetowa często pyta, na podstawie komunikatu o błędzie w pliku dziennika cat: http_home/favicon.ico: file or directory not found (nie znaleziono pliku lub katalogu).
Podsumowanie
Jak widać, przygotowanie własnego serwera WWW w Bashu jest dość proste – głównie dzięki Netcatowi, który wykonuje za nas większość skomplikowanych operacji związanych z obsługą połączeń TCP/IP, pozostawiając nam implementację bardzo ograniczonego podzbioru HTTP.
Przedstawiony w tym artykule serwer WWW ma prostą konstrukcję i oczywiście pod żadnym względem nie może konkurować z Apache czy Nginksem.
Z drugiej strony, samodzielna budowa serwera może nas wiele nauczyć na temat samego protokołu HTTP i zagadnień pokrewnych oraz standardowych i nieudokumentowanych zachowań przeglądarek. Co więcej, tego typu lekki serwer można łatwo rozbudować o niestandardowe rozwiązania; można go też użyć do prototypowania.
Źródła:
[1] Netcat: http://netcat.sourceforge.net/
[2] Kolejka: https://pl.wikipedia.org/wiki/Kolejka_(informatyka)
[3] Sed: https://www.gnu.org/software/sed/manual/sed.html
[4] Kody statusu HTTP: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes

