

Fuzzing to ważna metoda wyszukiwania błędów i luk w zabezpieczeniach oprogramowania. W niniejszym artykule wyjaśniamy, czym jest fuzzing i jakie jego metody są dziś powszechnie stosowane.
To była ciemna i burzowa noc. Bart Miller — pracował w domu, połączony 1200-bodowym modemem z komputerem typu mainframe należącym do Uniwersytetu Wisconsin. Jednak każde uderzenie pioruna powodowało, że coś poszło nie tak: piorun zakłócał transmisję danych przez linię telefoniczną i zniekształcał poszczególne znaki, zmuszając Millera do ciągłych restartów.
Za każdym razem, gdy ponownie nawiązywał połączenie, zauważał, że wiele programów nie radzi sobie z uszkodzonymi danymi – zawieszały się, wyświetlały błędy lub nagle przestawały działać. Czy programy nie powinny znacznie lepiej radzić sobie z nieprawidłowymi lub uszkodzonymi danymi wejściowymi? Miller postanowił, że jego uczniowie będą systematycznie badać ten problem i dał im zadanie programistyczne.
Tej jesiennej nocy 1988 roku umownie narodził się fuzzing, zdecydowanie najważniejsza obecnie metoda testowania programów pod kątem odporności na błędy i sprawdzania luk w zabezpieczeniach. Profesjonalni programiści rutynowo używają fuzzingu do prowokowania problemów, które mogą wystąpić po wydaniu bądź wdrożeniu danego oprogramowaniu i które często trudno przewidzieć. Jednak fuzzing jest nadal tajemnicą dla wielu programistów pracujących w niepełnym wymiarze godzin i zaawansowanych użytkowników, którzy programują nieformalnie (w tym wielu członków społeczności Linuksa). W tym miesiącu przyjrzymy się bliżej fuzzingowi i wyjaśnimy, dlaczego jest tak ważny.
Czym jest fuzzing?
Odpowiedź na to pytanie można znaleźć w zadaniu, które Bart Miller przygotował swoim studentom: „Celem tego projektu jest ocena odporności różnych programów narzędziowych działających w systemie Unix na strumień nieprzewidywalnych danych wejściowych. Ten projekt składa się z dwóch części. Najpierw powinieneś zbudować generator, który wytworzy losowy strumień znaków. Następnie weźmiesz generator i użyjesz go do zaatakowania jak największej liczby narzędzi uniksowych, próbując je popsuć”.
To zadanie programistyczne podsumowuje podstawową ideę fuzzingu: automatycznie generujemy losowe dane wejściowe, po czym sprawdzamy, czy zasilane nimi programy robią nieprzewidywalne rzeczy; te dwie fazy powtarzamy często i szybko.
W tym procesie fuzzery wykorzystują różne techniki wyszukiwania błędów. Najprościej jest wygenerować czysto losowe dane wejściowe; w ten sposób można znaleźć błędy w przetwarzaniu danych wejściowych, takie jak przepełnienie bufora. Fuzzery oparte na modelach wykorzystują gramatyki i inne modele językowe do generowania prawidłowych i ukierunkowanych danych wejściowych. Fuzzery oparte na ewolucji mutują dane wejściowe, aby znaleźć warianty, które spowodują wykonanie jak największych obszarów kodu. Fuzzery oparte na ograniczeniach mogą wykorzystywać złożone ograniczenia w kodzie programu, ale zajmuje to dużo czasu.
Polskie tłumaczenie słowa „fuzzing”
Na razie słowo „fuzzing” nie ma dobrego odpowiednika w języku polskim. Niektórzy autorzy używają terminu „testy rozmyte”, przez analogię do „logiki rozmytej” (ang. fuzzy logic) i powiązanych pojęć (takich jak zbiór rozmyty czy implikacja rozmyta). Naszym zdaniem nie jest to idealne rozwiązanie: w logice rozmytej mamy faktycznie do czynienia ze swojego rodzaju rozmyciem – terminom mało precyzyjnym (czyli właśnie „rozmytym”), takim jak „ciepły” czy „zimny” przypisywane są precyzyjne zakresy wartości. Natomiast w fuzzingu chodzi o przekazywanie programom nieprawidłowych danych wejściowych, często losowych (słowo „fuzz” oznacza dosłownie kłaczki kurzu). Być może więc zamiast „testowania rozmytego” bardziej precyzyjnym – choć mało eleganckim – polskim odpowiednikiem byłoby po prostu „zaśmiecanie wejścia”.
Fuzzing z czysto losowymi danymi wejściowymi jest bardzo prosty do przeprowadzenia: wystarczy kilka wierszy kodu, by wygenerować niezbędne dane wejściowych. Na przykład przedstawiona na Listingu 1 funkcja fuzzer() generuje ciągi losowych znaków, które wyglądają mniej więcej tak:
!7#%”*#0=)$;%6*;>638:*>80″=(/*
:-(2<4 !:5*6856&?””11<7+%<%7,4.8+
Bart Miller określił ten rodzaj danych wejściowych jako fuzz, co oznacza nieustrukturyzowane, losowe dane. Co może zrobić fuzz? Wyobraźmy sobie, że przekazujemy ten ciąg programowi, który oczekuje pięciocyfrowego kodu pocztowego. Jeśli ma bufor na pięć znaków na wejście, ale rzeczywiste wejście przekracza jego pojemność (powyższy fuzz ma więcej niż 60 znaków), może wystąpić przepełnienie bufora. Obszary pamięci poza pięcioznakowym buforem są nadpisywane przez dane wejściowe w mniej więcej losowy sposób, co z kolei powoduje, że program zachowuje się mniej więcej losowo. Może się np. zawiesić lub wejść w nieskończoną pętlę podczas próby odczytania pięciu cyfr.
Listing 1: Prosty Fuzzer w Pythonie
import random
def fuzzer(max_length=100, char_start=32, char_range=32):
„””Generate a string of up to `max_length` characters
in the range [`char_start`, `char_start` + `char_range` – 1]”””
string_length = random.randrange(0, max_length + 1)
out = „”
for i in range(0, string_length):
out += chr(random.randrange(char_start, char_start + char_range))
return out
Jeśli program otrzyma dane wejściowe za pośrednictwem strony internetowej, atakujący może na przykład wprowadzić do formularza ciąg podobny do powyższego i w ten sposób spróbować zakłócić działanie programu lub uczynić go bezużytecznym. Próby wstrzyknięcia nieprawidłowych danych mogą następować miliony razy na minutę: wystarczy usiąść wygodnie i pozwolić generatorowi wykonać swoją pracę; awaria może nastąpić po kilku godzinach, dniach czy nawet tygodniach.
Jednak nie zawsze rezultatem musi być awaria. Ponieważ przepełnienia bufora mogą również nadpisać krytyczne dane, takie jak hasła, a nawet kod programu, możliwe jest zaprojektowanie danych wejściowych w taki sposób, aby atakujący przejął kontrolę nad programem, a nawet komputerem. Ta część pracy nie jest jeszcze tak zautomatyzowana jak sam fuzzing; ale jeśli się powiedzie, czeka nas ogromna nagroda.
Ogólnie rzecz biorąc, współczesny programy są (a przynajmniej powinny być) chronione przed takimi atakami. Zasadniczo nie należy ufać żadnym danym, które znajdują się pod kontrolą strony trzeciej (tj. pochodzą od użytkowników, innych komputerów lub innych programów). Aplikacja internetowa, która oczekuje pięciocyfrowego kodu pocztowego, powinna zatem upewnić się, że dane wejściowe faktycznie składają się z pięciu cyfr, już teraz sprawdzając formularz wejściowy, aby wiedzieć, czy dane wejściowe są prawidłowe. Serwer musi sprawdzić poprawność przesyłanych danych i wszystkie programy, które je przetwarzają, powinny zrobić to samo. Wreszcie, programy w sieci powinny zezwalać tylko na ograniczoną liczbę nieudanych, a następnie zablokować dostęp.
W 1988 r. takie mechanizmy były rzadkością, a to, co odkryli studenci Millera, było przerażające: w ciągu kilku sekund udało im się zawiesić ponad jedną trzecią wszystkich narzędzi uniksowych, przesyłając im losowe dane wejściowe. Wyobraź sobie, co by się stało dzisiaj, gdyby jedna trzecia wszystkich aplikacji internetowych była podatna na ataki w tak trywialny sposób — Internet, jaki znamy, zostałby przejęty w ciągu kilku sekund.
Jednak w 1988 roku Internet był jeszcze w powijakach i każdy administrator znał osobiście użytkowników swoich maszyn. Zresztą Miller miał początkowo problemy z opublikowaniem wyników swoich odkryć. Typowa reakcja administratorów brzmiała: „I co z tego? Dlaczego powinno mnie obchodzić, co się dzieje z nieprawidłowymi danymi? Moi użytkownicy przesyłają mi prawidłowe dane!”. Na szczęście programiści open source postrzegali ten problem inaczej i szybko zmodyfikowali swoje programy, my potrafiły zidentyfikować nieprawidłowe dane wejściowe i odrzucić je w kontrolowany sposób. W ten sposób większość programów GNU, a także samo jądro Linuksa szybko uodporniły się na fuzzing, a później – pozostałe programy, w tym komercyjne.
Struktura kodu pocztowego
<kod_pocztowy> := <cyfra><cyfra>-<cyfra><cyfra><cyfra> <cyfra> := 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Testowanie automatyczne
Kiedy już uodpornimy program na losowe łańcuchy znaków, generatorowi fuzz bardzo trudno jest znaleźć błędy. Dzieje się tak, ponieważ większość danych generowanych losowo jest nieprawidłowa. Załóżmy na przykład, że nasz program przetwarzający kod pocztowy generuje błąd dotyczący kodu 00–000 – być może dlatego, że taki kod jest niedozwolony. Jaka jest szansa na otrzymanie takich danych wejściowych przez przypadek? Jeśli (uproszczony) generator fuzz generuje dane wejściowe zawierające od jednego do 100 znaków, prawdopodobieństwo, że będzie to pięć znaków, wynosi 1:100. Załóżmy również, że generator generuje 10 różnych (drukowalnych) znaków, w tym 10 cyfr. Wtedy szansa na pojawienie się pięciu cyfr wynosi 1:105 (czyli jedna na 100 000). Szansa na pięć zer wynosi nawet 1:1005 (czyli jedno na 10 miliardów). Po pomnożeniu przez szansę, że w ogóle otrzymamy wartość wejściową o długości pięć, otrzymujemy jeden bilion. Nowoczesne aplikacje internetowe działają szybko, ale nawet jeśli przyjmiemy jedną milisekundę na interakcję, w najgorszym przypadku potrzebowalibyśmy 31 lat ciągłego przetwarzania danych, aby wykryć błąd wspomniany. Już większą korzyść przyniosłoby wydobywanie bitcoinów.
Jeśli jednak wiemy, jak zbudowane są dane wejściowe, możemy drastycznie zwiększyć swoje szanse, udostępniając tę wiedzę generatorowi. W tym miejscu do gry wkracza potężniejsza klasa generatorów, których zasada działania sięga 1972 roku. Fuzzery oparte na modelach wykorzystują specyfikację formatu wejściowego do generowania poprawnych danych wejściowych a priori, omijając liczne nieudane próby zawierające czysto losowe ciągi.
Jedną z dobrze znanych i dobrze rozumianych metod określania formatów wejściowych są gramatyki, które definiują strukturę danych wejściowych. Na przykład gramatyka przedstawiona w ramce „Struktura kodu pocztowego” opisuje strukturę kodu pocztowego. Taka gramatyka składa się z reguł, które określają strukturę pojedynczego elementu wejściowego: elementskłada się z pięciu bezpośrednio następujących po sobie cyfr, przy czym po dwóch pierwszych elementachnastępuje literał „-”. Z koleijest jedną z dziesięciu alternatyw oddzielonych znakiem |.
Fuzzer oparty na modelu używa tego rodzaju gramatyki do generowania danych wejściowych. Aby to zrobić, zaczyna od elementu wejściowego po lewej stronie (takiego jak) i zastępuje go tekstem po prawej stronie (-). Powtarza to, dopóki wszystkie symboliczne elementy wejściowe nie zostaną zastąpione. Jeśli po prawej stronie jest kilka możliwości do wyboru, wybiera losowo jedną z nich. W ten sposób fuzzer zastępuje każdy element wejściowyjedną z cyfr od 0 do 9, dzięki czemu generuje, powiedzmy, ciąg losowy 43–672. Może to być również 34–829 lub 12–456 – tak czy inaczej, będzie to pięć cyfr.
Korzystając z tej gramatyki, szansę na znalezienie problematycznego kodu pocztowego 00–000 można zmniejszyć do 1:100 000. To wciąż duża liczba, ale nawet fuzzery oparte na modelach generują miliony danych wejściowych w ciągu kilku minut. I w przeciwieństwie do czysto losowych danych wejściowych, ich dane wejściowe są zawsze prawidłowe, mogą zatem przeniknąć wewnątrz programu i w ten sposób znaleźć błędy logiczne, niezwiązane nawet z przetwarzaniem danych wejściowych.
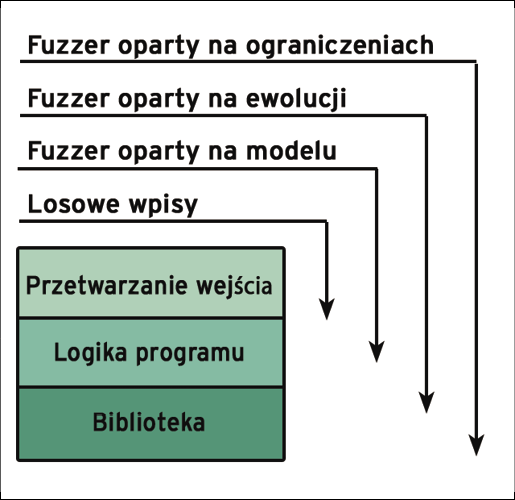
Gdzie fuzzery znajdują błędy
Chociaż mechanizmy przetwarzania danych wejściowych generalnie odrzucają dane czysto losowe, fuzzery oparte na modelach i ewolucji mogą łatwiej zagłębić się w logikę programu. Fuzzery oparte na ograniczeniach – jeszcze bardziej (Rysunek 1). W rzeczywistości fuzzery oparte na modelach można łatwo wykorzystać do generowania nawet złożonych danych wejściowych. Na przykład gramatyka przedstawiona w ramce „Gramatyka adresów” generuje dane adresowe.
Na podstawie reguł dlamożemy wygenerować np. rekord Jan Kowalski, Mickiewicza 10, 00–950 Warszawa. Reguły dlaigenerują odpowiednio sekwencję cyfr i liter, co skutkuje bardziej nietypowymi rekordami, takimi jak Anton GJK, EIUYLHK 00, 23–165 Kraków.
Gramatyka adresów
<adres> := <imię> <nazwisko>, <ulica> <numer_domu>, <kod_pocztowy> <miasto>
<imię> := Jan | Maria | … | <losowa_nazwa>
<nazwisko> := Kowalski | Nowak | … | <losowa_nazwa> <miasto> := Kraków | Warszawa | <losowa_nazwa> <ulica> := Mickiewicza | Jana Pawła II | <losowa_nazwa> <numer_domu> := <cyfra> | <numer_domu><cyfra> <losowa_nazwa> := <litera> | <losowa_nazwa><litera> <litera> := A | B | C | … | Z
Wstrzykiwanie SQL za pomocą gramatyki
<miasto> := Warszawa | Kraków | <losowa_nazwa> | <SQL_injection>
<SQL_injection> := ’); DROP TABLE addresses;
Ponieważ użytkownik może tworzyć i rozszerzać gramatyki, umożliwiają one lepsze ukierunkowanie fuzzera. Na przykład tester bezpieczeństwa może dodać do opisanej wyżej gramatyki wstrzykiwanie SQL, czyli atak polegający na umieszczeniu w danych wejściowych poleceń bazodanowych (patrz ramka zatytułowana „Wstrzykiwanie SQL za pomocą gramatyki”).
Ten konkretny atak dodaje polecenia SQL do adresów, co może prowadzić do usunięcia danych, jeśli dane wejściowe nie zostaną poprawnie sprawdzone. Jest więc oczywiste, że wszelkie eksperymenty z fuzzingiem powinny być przeprowadzane tylko w kontrolowanym środowisku na własnym komputerze. W niektórych jurysdykcjach tego typu testy na komputerach należących do osób trzecich są karalne.
Testowanie oparte na gramatyce jest szeroko rozpowszechnione w praktyce, ale służy przede wszystkim do testowania własnych programów – przede wszystkim dlatego, że gramatykę można zawsze dostosować do konkretnych celów testu, ale nie tylko. Na przykład Mozilla i Google znalazły i naprawiły tysiące problemów w interpreterach JavaScriptu za pomocą opartego na gramatyce narzędzia Langfuzz [1], który generuje programy w JavaScripcie. Z kolei w testach kompilatorów powszechnie stosowany jest program do generowania poprawnych programów w C o nazwie Csmith [2]. Bazujący na modelach FormatFuzzer [3] specjalizuje się w binarnych danych wejściowych, takich jak pliki obrazów lub archiwa. To, że możemy w miarę bezpiecznie korzystać z zasobów WWW zawdzięczamy w dużej mierze fuzzingowi opartemu na modelach.
Sukces dzięki mutacji
Mimo całej swojej mocy fuzzery oparte na modelach mają jedną poważną wadę: zanim ich użyjemy, musimy dla nich napisać gramatykę. W przypadku rzadkich lub specyficznych dla aplikacji formatów wejściowych wymaga to znacznego nakładu pracy, zwłaszcza jeśli musimy najpierw zrozumieć dany format. Jeśli jednak dysponujemy przykładowymi danymi wejściowymi, możesz wypróbować najmłodszą klasę generatorów testowych: generatory oparte na ewolucji.
Tego typu narzędzia mają również na celu wygenerowanie możliwie najbardziej poprawnych danych wejściowych, aby zagłębić się w program. Jednak osiągają ten cel nie za pomocą opisu danych wejściowych, takiego jak gramatyka, ale systematycznie zmieniając (mutując) istniejące dane wejściowe. Rozważmy na przykład niemiecki adres: Mickiewicza 71, 00–950 Warszawa. Mutacja może polegać na zamianie znaków miejscami: Mikciewicza 17, 00–590 Warzsawa. Alternatywnie można zastąpić jeden znak innym (Mitkiewicza 71, 00–950 Warsiawa) lub usuwać losowe znaki (Mikiewica 7, 00–95 Warawa).
Każda mutacja dostarcza zatem nowych danych wejściowych do testu. Zakres zmienności nie jest tak duży, jak w przypadku czysto losowych danych wejściowych lub testów opartych na modelu, ale prawdopodobieństwo uzyskania prawidłowych danych wejściowych jest nadal wysokie. Na przykład w poprzednich przykładach usunięcie tylko jednej cyfry z kodu pocztowego powoduje, że adres staje się nieprawidłowy.
Ale prawdziwa siła fuzzerów opartych na ewolucji polega na tym, że używają mutacji do systematycznej ewolucji zestawu udanych danych wejściowych. Celem jest uwzględnienie jak największej liczby zachowań programu. W tym celu fuzzery utrzymują pewien zestaw szczególnie obiecujących danych wejściowych – jest to tzw. populacja. Zaczynamy od zestawu znanych i ważnych danych wejściowych, które mutują, zwiększając populację.
Fuzzer mierzy teraz, do których miejsc w programie docierają dane wejściowe (czyli jakie jest pokrycie). Dane wejściowe, które docierają do wcześniej odkrytych lokalizacji, są uważane za szczególnie obiecujące, tak więc zachowujemy je, posłużą nam bowiem za podstawę do dalszych mutacji. Natomiast te dane wejściowe, które nie docierają do nowych lokalizacji, są usuwane z populacji (co nosi nazwę selekcji). W ten sposób populacja cały czas ewoluuje, zmierzając do celu, którym jest dotarcie do jak największej liczby miejsc w programie, a tym samym uwzględnienie jak największej liczby zachowań programu.
W poprzednich przykładowych mutacjach, na przykład, ostatnia mutacja (00–95) zostałaby sklasyfikowana jako obiecująca, ponieważ jako pierwsza dotarłaby do kodu obsługi błędów z czterocyfrowym kodem pocztowym, a tym samym ujawniłaby nowe zachowanie programu. Z drugiej strony mutacja z Mickiewicza do Mikciewicza prawdopodobnie nie obejmuje nowego kodu; na dłuższą metę zostałaby usunięta z populacji – chyba że testujemy program zawierający mapowania poszczególnych kodów pocztowych na ulice polskich miast.
A co z szansą na wygenerowanie specjalnego kodu pocztowego 00–000? Jeśli kod jest skonstruowany tak, aby odpytywać bit po bicie kodu pocztowego, jak na Listingu 2, ponieważ każdy warunek częściowy jest spełniony, wykonywany jest inny fragment kodu, który sprawdza następną cyfrę. Po wielu uruchomieniach ciąg 81739zmutowałby najpierw do 01739, następnie do 00739, potem do 00039, a na koniec do 00–000, dzięki czemu fuzzer odkrywa coraz więcej kodu. Fuzzery oparte na ewolucji potrafią również wykryć częściowy sukces podczas porównywania ciągów znaków, dzięki czemu powoli dążą do celu, tworząc coraz więcej mutacji.
Fuzzery oparte na ewolucji przypominają naturalną ewolucję – należy się liczyć z wieloma nieudanymi testami, jednak podejście to jest na dłuższą metę skuteczniejsze. Co najważniejsze, jest stosunkowo proste: dane wejściowe są często dostępne lub można je pozyskać z konkretnych sekwencji. Co więcej, fuzzery oparte na ewolucji nie wymagają dodatkowej wiedzy na temat formatów wejściowych. Ich główną wadą jest zależność od dobrych danych wejściowych: jeśli początkowe dane wejściowe nie zawierają określonej cechy, jest mało prawdopodobne, że ta cecha kiedykolwiek zostanie wygenerowana.
Klasycznym fuzzerem opartym na ewolucji jest American Fuzzy Lop (AFL [4]), napisany przez polskiego specjalistę od bezpieczeństwa, Michała „lcamtufa” Zalewskiego, kiedy pracował jako dyrektor ds. bezpieczeństwa w Google. AFL to wysoce zoptymalizowany fuzzer, za pomocą którego Zalewski i inni wykryli liczne błędy w istniejących programach. Większość krytycznych dla bezpieczeństwa programów dla Linuksa jest obecnie testowanych przez całą dobę AFL i wywodzące się z niego programy, m.in. w projekcie Google OSS Fuzz.
Listing 2: Stopniowy test ciągu pięciu cyfr
if (len(zip) == 5 and zip[0] == '0′
and zip[1] == '0′ and zip[2] == '0′
and zip[3] == '0′ and zip[4] == '0′):
do_something_special()
O ile AFL i pochodne są używany głównie we „wrogich” scenariuszach, w których nie oczekuje się współpracy ze strony autorów programu, Sapienz [5] to oparty na ewolucji fuzzer, który jest używany przez Facebooka do testowania wewnętrznych programów i aplikacji. Bez względu na to, czy używamy wiersza poleceń w Linuksie czy z Facebooka na telefonie, korzystamy z efektów pracy twórców fuzzerów opartych na ewolucji.
Wykrywanie warunków
Czwarta klasa generatorów fuzz również ma na celu dotarcie do jak największej liczby miejsc w kodzie programu. Zamiast zasady prób i błędów, której używają oparte na ewolucji fuzzery, bazuje na systematycznym rozpoznawaniu i spełnianiu określonych warunków. Chodzi o warunki, których spełnienie powoduje obranie przez program określonej ścieżki, a tym samym dotarcie do określonego miejsca w kodzie.
W fuzzerach opartych na warunkach używane są wyspecjalizowane narzędzia do automatycznego wyszukiwania rozwiązania dla danego zestawu warunków. W przypadku kodu pocztowego takie narzędzie wygeneruje rozwiązanie 00000 w ciągu setnych części sekundy.
Takie narzędzia pokazują swoją prawdziwą siłę w złożonych obliczeniach arytmetycznych. Jeśli warunek jest podobny do tego z Listingu 3, generator określi również odpowiednie wartości dla x i y – i to w bardzo krótkim czasie, podczas gdy fuzzery oparte na gramatyce polegają na przypadku, a fuzzery oparte na ewolucji muszą mieć nadzieję, że ich początkowa populacja zawiera odpowiednie wartości dla x i y. Zatem tego typu fuzzery są szczególnie przydatne tam, gdy muszą być spełnione pewne określone warunki, zwłaszcza ukryte głęboko w logice programu. Pomagają również szybko rozpoznać nietrywialne właściwości pewnych plików wejściowych, takich jak np. sumy kontrolne.
Fuzzery oparte na warunkach są potężne, ale nie wszechmocne. Jeśli konieczne jest odzyskanie oryginału z zaszyfrowanego tekstu, nawet tego typu narzędzie najczęściej nie może zrobić nic więcej poza próbami odgadnięcia klucza. Co więcej, czas ich działania pozostawia wiele do życzenia. Fuzzery oparte na gramatyce lub ewolucji mogą czasami testować tysiące elementów wejściowych i – w zależności od złożoności ograniczeń – docierają do celu szybciej niż narzędzie fuzzery oparte na warunkach.
Listing 3: Przykład ograniczeń warunkowych
if x * x + y * y > 3
and x * x * x + y < 5:
do_something_interesting()
KLEE [6], bardzo popularny fuzzer tego typu, znalazł setki błędów w programach C. Microsoft używa własnego narzędzia o nazwie SAGE [7], który wykorzystuje gramatykę dokumentów Office do systematycznego wyszukiwania błędów w oprogramowaniu biurowym. Zaoszczędził on Microsoftowi i jego użytkownikom setki milionów dolarów. NASA również wykorzystuje fuzzery oparte na warunkach, aby przetestować każdą sytuację, jaką może napotkać statek kosmiczny [8].
Podsumowanie
Współczesne fuzzery już dawno przestały polegać na jednej technice i często łączą wiele z nich. Ostatecznie najbardziej skuteczne jest takie narzędzie, które najszybciej znajdzie najpoważniejsze błędy. Z tego punktu widzenia warto zacząć do prostych losowych ciągów znaków, aby najpierw wyszukać błędy w przetwarzaniu danych wejściowych, a następnie użyć danych wejściowych skonstruowanych za pomocą gramatyki lub ewolucji do wykrycia błędów na głębszych poziomach.
Gramatykę, ewolucję i warunki można łączyć na wiele sposobów. Która kombinacja jest najskuteczniejsza i w jakich warunkach – to przedmiot gorącej debaty wśród badaczy i programistów. Z punktu widzenia użytkownika rodzaj użytego fuzzera ma mniejsze znaczenie – najważniejsze jest, by dany program w ogóle był przetestowany fuzzerem. Oprogramowanie, które nigdy nie było narażone na działanie fuzzera, najprawdopodobniej zawiera błędy, które można wywołać, przekazując mu losowe dane wejściowe.
W przypadku programów napisanych w języku C można szybko uzyskać intersujące wyniki, używając fuzzerów takich jak AFL lub KLEE; potrafią one bardzo szybko wygenerować gramatykę dla prostych danych wejściowych. Ale dotyczy to zarówno twórców programów, jak i atakujących: jeśli sami nie użyjemy fuzzingu, ryzykujemy, że zrobią to inni i szybko wykorzystają znalezione błędy. Na początku trzeba włożyć nieco pracy w skonfigurowanie fuzzera, jednak potem możemy usiąść wygodnie i zrelaksować się: od tego momentu fuzzer przejmuje kontrolę, niestrudzenie testując nowe dane wejściowe, aż zapali się czerwone światło, sygnalizując, że znaleziono błąd. Od tego momentu rozpoczyna się rozwiązywanie problemów i odpluskwianie, które również można częściowo zautomatyzować.

